
A Guide to the AI Text Classifier
At its heart, an AI text classifier is a smart system that automatically sorts and labels text. Think of it as a digital librarian for your data, one that can instantly organize a flood of customer feedback, emails, or social media mentions into neat, meaningful categories without you lifting a finger.
What Is an AI Text Classifier

Imagine sifting through every single customer review your company gets, trying to manually sort them into piles for "Positive Feedback," "Urgent Issues," or "Feature Requests." For a small business, that's a soul-crushing task. For a large company, it's flat-out impossible. This is precisely the problem an AI text classifier is built to solve.
The technology essentially brings order to the chaos of unstructured text data. It’s designed to read and understand human language, then assign a specific label—or "tag"—to each piece of text based on what it's about. This simple act turns messy, qualitative information into clean, quantitative data you can actually analyze and act on.
The Digital Librarian Analogy
The best way to wrap your head around this is to picture a highly efficient digital librarian. All your unstructured text—emails, support tickets, tweets, internal reports—is like a giant, disorganized pile of books dumped on the library floor.
Instead of a human reading every cover and summary, this AI librarian scans the full content of each book in an instant. It grasps the topic, theme, and even the sentiment, then places it on the right shelf: "Customer Complaints," "Spam," "Positive Reviews," or whatever other custom categories you've set up. And this librarian works 24/7, never gets tired, and can sort millions of "books" in minutes.
A text classifier doesn't just scan for keywords; it understands context and intent. It's the engine behind your email's spam filter and the sophisticated systems that track public opinion about a brand.
The need for this kind of automation is exploding. The global Text Classification AI market, valued at roughly $3.2 billion in 2024, is projected to hit about $18.7 billion by 2033. You can dig into the specifics of this growth in the Text Classification AI market report. This incredible surge shows just how much businesses rely on tools like sentiment analysis and automated content moderation to stay competitive.
What an AI Text Classifier Actually Does
To get more specific, an AI text classifier performs several key tasks that turn raw text into structured insights. Here’s a quick breakdown of its core functions:
| Function | Description | Example |
|---|---|---|
| Sentiment Analysis | Gauges the emotional tone of text. | Labeling a customer review as "Positive," "Negative," or "Neutral." |
| Topic Labeling | Sorts text by its primary subject matter. | Tagging news articles as "Sports," "Technology," or "Finance." |
| Spam Detection | Identifies and filters unwanted messages. | Moving a suspicious email from your inbox to the spam folder. |
| Urgency Detection | Pinpoints high-priority items needing a fast response. | Flagging a support ticket with the words "account locked" for immediate action. |
Ultimately, the ability to automate these tasks is more than just a convenience. It gives businesses the foundation they need to make smarter, faster, and more data-driven decisions across the board.
How AI Learns to Understand Language
Before an AI can label a customer review as "positive" or a support ticket as "urgent," it has to learn how to read. This isn't about learning the alphabet like we do. It's a far more intricate process of teaching a machine to pick up on the context, patterns, and subtle shades of meaning in human language.
This entire field is known as Natural Language Processing (NLP), and it's the engine that powers every text classifier. NLP is the essential bridge that connects our messy, often chaotic language to the structured world of computer understanding. But how does this engine actually work? It all starts by breaking language down into pieces a machine can digest.
Deconstructing Language Into Data
A computer doesn't see sentences or paragraphs; it just sees raw data. So, the first step in NLP is to translate our language into a clean, organized format. This involves a few core techniques you'll see everywhere.
- Tokenization: This is really just a fancy word for chopping a sentence into individual words or "tokens." The sentence "This product is fantastic!" becomes the tokens: "This," "product," "is," "fantastic," and "!". It's the first, most fundamental step.
- Stemming and Lemmatization: Both techniques are about getting words down to their root form. Stemming is the quick-and-dirty method—it just lops off the end of words, so "running" and "runs" both become "run." Lemmatization is the smarter cousin; it uses a dictionary to find the true root word (the lemma), so it knows that "better" and "best" are both related to "good."
- Stop Word Removal: We use a lot of filler words like "the," "is," "and," and "a" that don't add much meaning for a classifier. These "stop words" are often filtered out so the model can focus on the words that actually carry the sentiment or topic.
This cleanup job is crucial, but we're still just left with a pile of words. For the AI to do any real work, it needs to turn those words into something it can actually calculate: numbers.
Turning Words Into Numbers
This is where the real magic begins. Through a process called vectorization, every single word is converted into a unique string of numbers, known as a vector. Imagine it like giving every word a specific coordinate on a massive, multi-dimensional map.
On this map, words with similar meanings are plotted close to one another. So, the vectors for "happy," "joyful," and "ecstatic" would all be clustered together in the same neighborhood. Meanwhile, a word like "unhappy" would be in a completely different part of town.
This "meaning map" is what allows the AI to grasp relationships and context. It’s not just matching keywords; it's calculating the distance between concepts. That's a far more powerful way to interpret what's being said.
This numerical representation is what lets the machine learning model spot patterns. It can learn that documents full of words from the "happy" neighborhood are usually labeled "Positive," while those from the "unhappy" region are almost always "Negative."
The Brains of the Operation: Machine Learning Models
With the text prepped and vectorized, a machine learning model is trained to recognize these patterns and make predictions. Different models are used for different jobs, each with its own strengths.
Classic Machine Learning Models
For years, the workhorses of text classification have been algorithms like Naive Bayes and Support Vector Machines (SVMs). They're efficient and still work surprisingly well for straightforward tasks like basic spam filtering or topic sorting, where the context isn't too complicated.
Modern Neural Networks
These days, however, more advanced models built on neural networks are the gold standard. Architectures like Transformers, which are the foundation for systems like GPT-4, are incredibly good at understanding the nuances of language. They can pick up on sarcasm, irony, and complex sentence structures that would fly right over the heads of older models.
Finetuning these large models for a specific classification task is how most state-of-the-art systems are built today. While text classification is a primary use, you can see similar pattern-recognition principles at play when you read our guide on what AI detectors look for in generated images and text.
By combining these clever data preparation steps with powerful learning algorithms, an AI text classifier goes from simply "reading" words to truly understanding and categorizing language at an incredible scale.
Real-World Examples of AI Text Classifiers in Action
It's one thing to talk about the theory behind an AI text classifier, but where the magic really happens is when these systems get to work in the real world. They aren't just abstract concepts; they are the engines running behind the scenes of countless apps you use every single day. By taking on the immense task of sorting and making sense of text, they free up thousands of human hours and reveal insights that would otherwise be lost in the noise.
From keeping your inbox clean to helping your favorite brands improve their products, AI text classifiers are already creating a ton of value. Let's dig into a few of the most common and powerful examples.
Fortifying Your Inbox with Spam Detection
The spam filter in your email is probably the most universal example of text classification at work. Think about it: email providers like Gmail and Outlook handle billions of messages daily, and a huge chunk of that is junk—phishing attempts, scams, or just plain old spam. It would be an impossible job for any human team to sort through that avalanche of email.
This is where an AI text classifier becomes a lifesaver. It’s trained on a massive dataset of emails already labeled as either “spam” or “not spam.”
Over time, the model learns to spot the tell-tale signs of junk mail:
- Suspicious Phrasing: It flags common scammy language like "urgent action required" or "congratulations, you've won."
- Weird Formatting: The classifier picks up on odd character use, aggressive capitalization, and sketchy-looking links that are classic red flags.
- Sender Reputation: It even looks at metadata, like the sender’s history and domain, to figure out if they’re trustworthy.
By weighing all these signals in a split second, the classifier makes a decision and shunts unwanted mail away from your main inbox. It’s more than just a cleanup tool; it’s your first line of defense against cyber threats.
Reinventing Customer Support and Feedback
For any business that deals with customers, managing support tickets and feedback can feel like trying to drink from a firehose. An AI text classifier can bring order to that chaos, helping customers get faster, more relevant help.
Picture a big online retailer getting thousands of support emails every day. A classifier can read each one instantly and sort it into the right bucket.
- Ticket Routing: A message with "shipping status" or "where is my order?" gets zapped over to the logistics team. An email mentioning a "broken item" or "doesn't work" goes straight to the returns department. This kind of instant triage slashes response times.
- Urgency Detection: The classifier can also spot high-priority problems. If a message contains phrases like "payment failed" or "account locked," it gets flagged for immediate attention, which can be the difference between keeping and losing a customer.
This goes beyond just sorting emails. AI classifiers are also being used for more specific jobs, like AI-powered survey analysis, which helps companies sift through open-ended feedback to spot trends and fix problems they might not have known existed.
By automatically sorting tickets, companies can slash manual work, boost first-response times by over 30%, and make sure the right expert is on the case from the get-go.
Gauging Public Opinion with Sentiment Analysis
How do people really feel about your latest product launch? What’s the buzz around your new marketing campaign? Getting answers used to mean running expensive surveys and focus groups. Now, an AI text classifier built for sentiment analysis can give you that feedback in real time.
This type of classifier is trained to read a piece of text and label it as "positive," "negative," or "neutral." Businesses use this to keep a finger on the pulse by monitoring:
- Social Media Mentions: Tracking what people are saying about their brand on platforms like Twitter and Facebook.
- Product Reviews: Diving into reviews on sites like Amazon or Yelp to see what customers love and what they hate.
- News Articles: Understanding media perception around company announcements or big industry news.
This is a huge piece of the broader text analytics market, a sector projected to explode from $11.98 billion in 2024 to $41.86 billion by 2030. That incredible growth is all thanks to the massive value companies get from understanding customer sentiment at scale.
And it’s not just for giant corporations. Small businesses can use sentiment analysis to tune their products and services based on what their customers are saying. While today's tools are incredibly sophisticated, it's interesting to look back at the pioneers, like the now-retired OpenAI AI text classifier, which helped lay the groundwork for the systems we rely on today.
A Practical Guide to Building Your Classifier
Knowing what an AI text classifier is is one thing, but actually building one is where the real fun begins. It might sound like a job for a team of PhDs, but the process is surprisingly logical. Let's walk through the roadmap, turning that abstract concept into a working tool.
https://www.youtube.com/embed/BO4g2DRvL6U
Think of it less like complex coding wizardry and more like a structured, repeatable cycle. Each stage sets up the next, and getting the early steps right is absolutely essential. It's like building a house—you can't start framing the walls until you have a rock-solid foundation.
The Foundation: Data Collection And Preparation
It all starts with data. Your model is only ever going to be as smart as the information it learns from, making this the single most important part of the entire project. The goal here is to gather a large, representative set of text examples, with each one accurately labeled with the category you want the AI to predict.
So, if you're building a sentiment analyzer, you'll need thousands of customer reviews, and each one needs to be tagged as "positive," "negative," or "neutral."
This process breaks down into a few key steps:
- Data Sourcing: This could mean exporting customer feedback from your e-commerce platform, pulling public data from social media, or tapping into your internal support ticket archives.
- Labeling: This is usually the most time-consuming piece of the puzzle. You or your team will need to manually go through the text and assign the correct category. Consistency is everything here.
- Cleaning: Raw text is always a mess. This step is about stripping out the junk—like HTML tags, special characters, and duplicate entries—to create a clean, uniform dataset for the model to learn from.
The quality of your labeled data is the single biggest predictor of your model's success. A smaller, high-quality dataset will almost always outperform a massive, poorly labeled one. Garbage in, garbage out.
A classic mistake is creating an imbalanced dataset, where you have way more examples for one category than the others. For instance, if 95% of your reviews are "positive," the model might just get lazy and learn to guess "positive" every single time. You can fix this with techniques like over-sampling the minority classes or under-sampling the majority ones.
This visual flow shows how classifiers are applied in common business processes, from analyzing customer reviews to filtering spam and routing support inquiries.
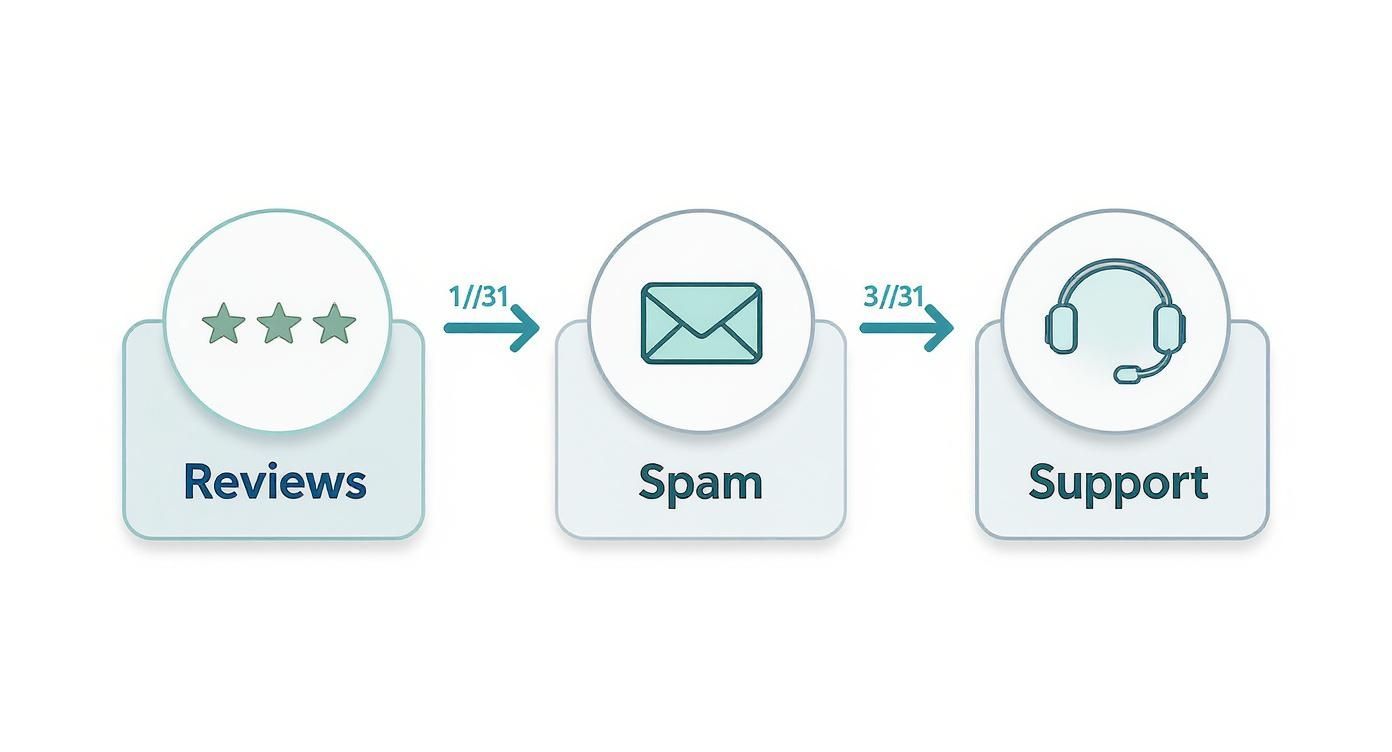
The infographic really highlights the journey from raw text to an automated, categorized output, showing the classifier's role as a kind of central sorting engine for modern workflows.
Model Selection And Training
Once your data is clean and labeled, it’s time to pick the right tool for the job. The good news is you don't need to build a model from the ground up. There's a whole ecosystem of open-source libraries and platforms that make this much more accessible.
For a team that isn't made up of pure data scientists, there are two fantastic starting points:
- Scikit-learn: This is a brilliant Python library packed with classic machine learning models like Naive Bayes and Support Vector Machines (SVMs). It’s perfect for smaller datasets and more straightforward classification tasks.
- Hugging Face: This is the go-to platform for working with modern Transformer-based models. It gives you access to incredibly powerful pre-trained models that you can then fine-tune on your specific dataset, often delivering top-tier performance with less data.
The training phase is where the magic happens. You feed your prepared dataset to the model, and its algorithm gets to work, adjusting its internal wiring to find the patterns that connect a piece of text to its label. This isn't a one-and-done deal; the model makes predictions, checks them against the correct answers, and refines its approach over and over again.
Comparing Text Classification Model Approaches
Choosing a model often feels overwhelming, but it really comes down to the trade-offs between complexity, performance, and the kind of problem you're trying to solve. Here’s a quick breakdown of some common approaches to help you decide.
| Model Type | Best For | Complexity | Example Libraries |
|---|---|---|---|
| Naive Bayes | Simple tasks like spam filtering and document sorting. Works well with smaller datasets. | Low | Scikit-learn, NLTK |
| Support Vector Machines (SVMs) | High-accuracy tasks with clear separation between categories, like sentiment analysis. | Medium | Scikit-learn, LIBSVM |
| Recurrent Neural Networks (RNNs) | Analyzing sequential data where context matters, like language translation. | High | TensorFlow, PyTorch |
| Transformer Models (e.g., BERT) | Complex language understanding tasks requiring deep contextual awareness. | Very High | Hugging Face Transformers |
As you can see, there's no single "best" model. Simpler models like Naive Bayes are fast and easy to implement, while advanced Transformer models offer incredible performance but require more data and computing power. Your choice depends entirely on your project's specific needs.
The Final Stretch: Evaluation And Iteration
After training, you have to find out if your model actually works. To do this, you use a slice of your data that the model has never seen before, called a test set. You'll measure its performance using a few key metrics to really understand its strengths and weaknesses.
Just looking at overall accuracy won't cut it. You need to dig deeper. For example, is it great at spotting "positive" reviews but completely misses "urgent" support issues?
This evaluation step gives you the clues you need to go back and make things better. Maybe you need to label more data for a specific category, or perhaps it's time to try a different model architecture altogether. Building an AI text classifier is almost never a one-shot process. It’s a cycle: build, test, learn, and refine until the model is good enough to deliver real value.
Measuring Your Classifier's Performance

So, you've built an AI text classifier. That's a huge step, but the real question is: how do you know if it's any good? Just because it’s making predictions doesn’t mean they’re the right ones. This is where performance evaluation comes in. Think of it as the report card for your AI model, showing you exactly where it shines and where it's falling short.
Looking only at overall accuracy can be a trap. Seriously. Imagine a classifier designed to spot urgent support tickets, but only 2% of all tickets are truly urgent. A lazy model that just labels every single ticket "not urgent" would be 98% accurate... and completely useless. We need better tools to get the full story.
Beyond Simple Accuracy
To really get a feel for your model's performance, we need to look at a few key metrics that paint a much more detailed picture. Let’s use a classic example everyone understands: an email spam filter.
- Precision: Out of all the emails your filter dumped into the spam folder, how many were actually junk? High precision means your filter isn't mistakenly flagging important emails (what we call low false positives).
- Recall: Of all the actual spam emails that hit your account, how many did your filter successfully catch? High recall means very little spam is slipping through into your main inbox (low false negatives).
- F1-Score: This metric is the sweet spot between precision and recall. It gives you a single, balanced score, which is super helpful when you need a model that's both careful and comprehensive.
There's almost always a trade-off between these two. If you crank up your spam filter to be extremely precise—only flagging things it’s absolutely certain are spam—its recall will likely drop, because it will start missing some of the trickier spam messages. Finding the right balance depends entirely on what you're trying to achieve.
A spam filter needs high precision. You’d probably rather a few junk emails slip into your inbox than have an important job offer go to the spam folder. But for a medical diagnosis model? High recall is everything. You'd much rather have a false alarm than miss a real case.
The need for reliable performance metrics is more important than ever. The AI text generator market, a close cousin to classifiers, was valued at $392 million in 2022 and is expected to rocket to $1.4 billion by 2030. This boom means we have to build tools that aren't just clever, but verifiably effective.
Visualizing Performance with a Confusion Matrix
Numbers are great, but sometimes a picture is worth a thousand data points. A confusion matrix is a simple table that shows you exactly where your model is getting things right and where it’s getting, well, confused. It breaks down every prediction into four buckets:
- True Positives (TP): Your model correctly identified the positive class (e.g., it flagged a spam email as spam). Nailed it.
- True Negatives (TN): Your model correctly identified the negative class (e.g., it correctly let a normal email into your inbox). Correct again.
- False Positives (FP): Your model messed up, flagging something as positive when it wasn't (e.g., a real email got sent to spam). This is a Type I error.
- False Negatives (FN): Your model missed something it should have caught (e.g., a spam email slipped into your inbox). This is a Type II error.
A quick glance at this matrix can tell you if your model has a bias toward one type of mistake over another. As you work on refining your model, looking into more advanced techniques like answer classification for chatbots can give you a significant edge. Ultimately, the question of performance is central to all AI tools, a topic we explore more in our article about whether AI detectors are accurate. You can read it here: https://www.aiimagedetector.com/blog/are-ai-detectors-accurate.
Common Questions About AI Text Classifiers
As you start working with AI text classifiers, a few questions always seem to come up. Let's tackle some of the most common ones to clear up any confusion and solidify what you've learned.
Is This the Same as Sentiment Analysis?
This is a big one. It's easy to mix up text classification and sentiment analysis, but the distinction is actually pretty simple.
Think of text classification as the umbrella term for sorting text into any kind of bucket you define. You could be classifying customer support tickets into categories like ‘Billing Question’ or ‘Technical Issue.’ Or maybe you’re sorting news articles by topic: ‘Sports,’ ‘Politics,’ ‘Technology.’
Sentiment analysis is just a very specific type of text classification. Its only job is to figure out the emotional tone of a piece of text, usually sorting it into ‘positive,’ ‘negative,’ or ‘neutral’ buckets. So, all sentiment analysis is text classification, but not all text classification is sentiment analysis.
How Much Data Do I Need? And What About Other Languages?
The classic "how much data?" question. The honest, if unsatisfying, answer is: it really depends on the job. For a simple task with only two categories, you might get away with a few thousand examples. But if you’re trying to classify text into dozens of highly specific categories, you'll likely need tens of thousands of clean, labeled examples to get the job done right.
Here's a pro tip: transfer learning is your best friend. Instead of building a model from zero, you can take a massive, pre-trained model and fine-tune it with your smaller, specific dataset. This approach can get you fantastic results with a fraction of the data.
And what about languages? In theory, a classifier can work with any language. In practice, the world of AI is very English-centric. Top-tier models and massive training datasets are overwhelmingly available for English. While multilingual models are getting better, building a great classifier for a less common language can be tough simply because there isn't enough high-quality training data out there.
What Are the Biggest Roadblocks in Practice?
When you move from theory to a real-world project, a few hurdles pop up again and again. Here are the four biggest challenges you're likely to face:
- Getting Good Data: Finding or creating a large set of accurately labeled training data is almost always the hardest part. It can be incredibly expensive and time-consuming.
- Handling Nuance: People are complicated. Sarcasm, irony, and subtle cultural context can fly right over a model's head, leading to silly mistakes.
- Dealing with Model Drift: Language is always changing. A model trained on last year's slang might not understand this year's memes, causing its accuracy to drop over time.
- Defining Success: It’s easy to get lost in the technical details. The real challenge is making sure the model you build and the metrics you track actually solve the business problem you started with.
At AI Image Detector, we focus on providing clear, accurate analysis to help you distinguish between human and AI-generated content. If you need to verify an image's origin, our tool delivers fast, reliable results. Try it for free today.

